大型語言模型為什麼能用少量資料就做好事?
大型語言模型(LLM)有個很厲害的地方,就是即使只給它少量的資料,它也能在特定問題上表現得很好。這跟傳統的機器學習差異很大,因為傳統方法通常需要大量標註過的資料。而LLM透過一些獨特的技巧,像是Few-shot、Zero-shot學習,以及基於Transformer的技術,讓它能夠靈活應對不同任務。
Few-shot 和 Zero-shot 是什麼?
簡單來說,Zero-shot學習就是模型在完全沒見過某個任務資料的情況下,依然能夠做出不錯的預測。而Few-shot學習則是當你只提供少量資料時,模型依然能提高它的表現。這些能力來自於模型在大量資料上已經做過預訓練,學會了很多通用的知識和語言模式。所以,即使你只餵給它一點點特定領域的資料,它也能理解並處理。
這就好像模型已經有很強的基礎知識,你只要稍微指導一下,它就能應對新挑戰。
Transformer架構是怎麼一回事?
大型語言模型的成功很大程度上要歸功於Transformer架構,這是一種神經網路架構,包含兩個重要部分:編碼器(encoder)和解碼器(decoder)。編碼器負責讀取和理解輸入的內容,然後把這些訊息交給解碼器去生成答案。
舉個例子,假設你輸入了一句法語"Je suis étudiant",編碼器會理解這句話的意思,然後解碼器會產生對應的英文翻譯"I am a student"。這套系統能處理各種語言和任務,不需要依賴大量的資料,也能準確完成工作。
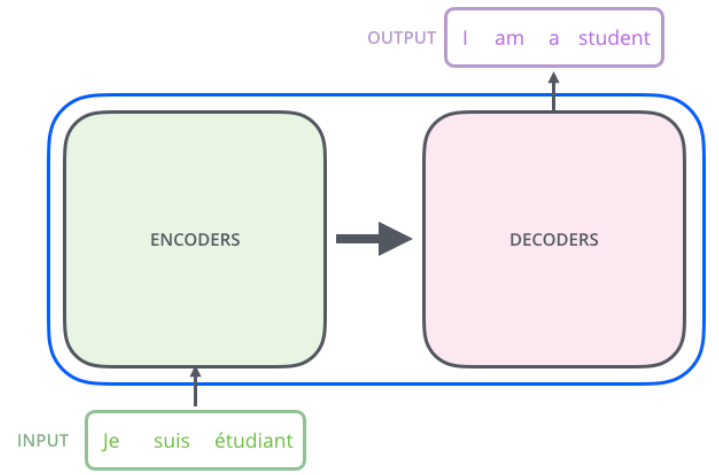
圖一: Transformer原理圖
預訓練和微調,讓模型更聰明
Transformer架構的另一個優勢就是它有**預訓練(Pre-training)和微調(Fine-tuning)**這兩個步驟。模型先在大量不同類型的資料上學習,掌握語言的基本規則,這就是預訓練。接下來,當遇到特定任務時,只需要給它少量的相關資料,經過微調,它就能適應並解決這些問題。
這樣,你不需要花大量時間準備資料,也不必具備專業的知識,只要設計一個簡單的提示(Prompt Design),模型就能幫你完成任務。
為什麼大型語言模型這麼厲害?
跟傳統的機器學習不同,大型語言模型不僅能處理文字,還能處理圖片、聲音等各種資料。比如,你不需要像以前那樣為貓咪的圖片標註很多細節(例如貓咪有幾隻腿、耳朵在哪等)。只要把貓咪的圖片、描述丟進模型,它就能告訴你這是貓咪,甚至能生成一張可愛的貓咪圖片。
這種靈活性讓大型語言模型即使在少量資料的情況下,依然能表現出色,這也是它相較於傳統方法的一大突破。
結論
簡單來說,大型語言模型透過Few-shot、Zero-shot學習和Transformer架構,再加上預訓練和微調,讓它即使在少量資料下也能處理各種問題。而且這種方式大大降低了我們準備資料和學習的成本,真的是讓工作變得更簡單的好幫手。
(圖一):transformer原理 | More Than Code
https://thomas-li-sjtu.github.io/2021/08/03/transformer/


 iThome鐵人賽
iThome鐵人賽